客服系统全套源码:大模型+RAG知识库解决方案,私有化部署AI智能客服源码

虽然现在大模型越来越聪明,但因大模型不了解企业真实情况所以很多时候无法准确回复顾客提问,为此需要引入RAG知识库来让AI智能客服系统在回复时有理有据,更智能更精准的回复访客。为此我们把RAG知识库引入到了PHP客服系统源码中,客服只需要把txt word等文档上传到知识库,客服系统就能自主学习训练,按知识库回复访客的问题,大大节省了人工成本,极大的提升了企业满意度。
把RAG知识库与客服系统源码结合会面临一些现实的技术问题,例如传统PHP框架的性能问题,如何分段、如何训练、如何索引、如何有效的召回知识库中知识,如何选择过滤无用的噪音,如何把知识按相关度排序等等。为此我们查阅了大量的前沿文章,手动做了大量优化与实验,取得了非常好的效果。
以下是实现99客服系统+RAG知识库遇到的问题和解决方案分享。
获取客服系统源码
如果你们公司想私有化部署自己的AI智能客服系统,请访问 99客服系统源码
测试地址
测试地址 https://live.99kf.com/kefu/login
测试账号 demo
密码 abc123
一 智能回复为什么要配合RAG知识库
纯大模型在客服里常见两类问题:
幻觉 当大模型不知道具体的情况时会一本正经的乱说
成本 如果强行把所有文档知识发给大模型会造成相当高的输入成本,并且因为各种文档的噪音会导致回复效果大打折扣。属于费力不讨好的情况。
RAG的作用 是只从知识库里获取必要的知识片段,通过一些过滤排序等算法,把最需要的知识片段发给大模型,大模型就能根据用户的提问以及知识片段总结回复给用户,不仅成本低,而且效果好。
二 RAG知识库难点及解决方案
如何精准分段
因为企业文档数量多,大小不一,所以需要把他们按照一定规则精准分段。
-
按固定大小分段(最常见)
按固定的字符数或 Token 数切分,并设置重叠区。
方法:例如每 512 个 Token 一段,重叠 10%-20%。
优点:简单、计算成本低、适合通用文本。
缺点:容易切断句子或语义单元,破坏连贯性。 -
基于语义边界的分段
尊重自然语言的边界,如句子、段落、章节来分段。
2.1 句子级分段
方法:以句号、问号、换行等为分割点。
优点:语义相对完整、粒度细,适合事实型问答。
缺点:可能把段落拆散。
2.2 段落级分段
方法:按\n\n或自然段切分。
优点:段落不会被拆散,不会丢失上下文细节。
缺点:段落长度差异大,可能超过模型限制,不过现在一般大模型都有超长上下文了。
2.3 递归/层次分段 (最终方案)
方法:先按章节切,再对超长块递归使用更小粒度(如段落)切分。
优点:适应不同长度内容,保留结构层次。
如何训练知识库
分好段后,我们需要做类似知识库训练的操作,实际上是把知识看的文档片段按照一些方案做索引,方便检索时能精准召回。
训练知识库方案如下:
- 标题索引
利用大模型为每个文档片段总结标题。 - 问题索引
利用大模型为每个文档片段总结用户针对此片段可能提出的问题,这里非常考验提示词技巧,既要尽可能多的展示各种问法,也不能让某些关键词占用过多的篇幅导致索引失真。 - 意图索引
利用embedding技术得到问题片段的向量建立意图索引。
训练流程这里因篇幅问题省略。
意图识别
知识库训练好后就可以等待用户提问,并根据提问来检索知识库召回相关知识片段。
但是这里在召回之前实际上需要一步意图识别,否则召回的知识可能是无用的知识,甚至可以根本不做召回,直接回复用户。
提炼提问
例如以下对话:
用户:现在有哪些型号
AI客服:现在有 A100 A101 你想了解哪个?
用户:第一个这时候如果用最后一个提问第一个去知识库检索,那么肯定无法得到有用的知识,大模型就无法准确回复。
所以,在检索知识库前需要识别意图,提炼用户问题,包括指代消解、去掉无意义关键词等。意图识别后提炼最终的结果为A100详细信息,然后以这个提炼去检索知识库才会让大模型回复准确的答案。
识别意图
意图识别除了提炼问题,还有一个重要的作用就是识别用户是闲聊还是针对知识库提问。如果是闲聊,则不需要检索知识库,直接回复用户即可。例如如下对话:
用户:你好啊短路径策略
有时候用户的条消息明显不需要调用大模型,则直接返回即可,这样既能节省开销,又能减少客户的等待。
例如用户的消息是 你好 我们直接返回 你好,有什么可以帮您?即可。
例如用户的消息是 谢谢,我们可以直接回复 不客气 即可。
这样的例子很多,我们可以把他们放到段路径规则中,快速响应。
如何精准召回
-
关键词检索
由于我们提前给标题+问题+内容做了全文索引,所以我们可以轻易的利用关键词把知识库中的命中关键词的知识片段召回。
优点 检索速度快;关键词检索非常适合那种精确的找找,例如访客询问某个具体型号的产品信息时。
缺点 如果用户提问的关键词与全文索引的关键词不一致,则无法搜索到,这时候需要语义检索。 -
语义检索
语义检索就是就是使用问题对应的向量来检索知识库,它能够识别语义,例如 它能理解“死机”≈“无响应”,当向量搜索死机了怎么处理时会把无响应如何处理等语义相近的检索出来。
优点 能匹配同义词、近义词、不同表达方式,不需要问题命中关键词。支持自然语言问句
不需要用户拆解为关键词,支持一定程度的跨语言。
缺点 需要额外的计算向量;精确匹配弱,例如对于检索特定关键词没有全文索引效果好。 -
多路召回
基于以上全文检索和语义检索的特点,我们采用二者结合的方式做多路召回,这样能发挥各自的优点,也能弥补缺点,尽可能的将所有需要的知识召回给大模型,提高回答质量。
选择排序
多路召回时可能会召回很多知识,这里有与问题密切相关的知识,也有不那么密切的,也有没有太大作用可删除的知识,所以我们需要做一种过滤+排序的机制。为此,我们将每种召回方案的记录排序,最相关的排在前面,然后利用RRF加权融合算法来重新排序。如果最终的知识片段很多,我们还会再做一次大模型选择排序,把不相关的知识排除掉,只保留相关的知识。
服务降级策略
因为大模型是外部网络调用,可能会发生调用失败的情况,在任何非关键路径调用外部大模型接口失败时,都需要做服务降级策略,例如向量生成失败时则忽略向量检索,大模型排序失败时则忽略大模型排序步骤等等,目的是让服务在任何时候都能尽可能的高可用。
三 传统PHP架构遇到的挑战
传统PHP框架是运行在PHP-FPM上的,每个请求会占用一个进程,我们知道大模型调用是一个漫长等待的过程,尤其是知识库这种有多次大模型接口调用的时候,这就会导致一个问题请求会占用一个PHP-FPM进程数秒的实践,最终导致服务器一分内只能支持非常有限的用户访问,大大降低了系统的吞吐量,造成用户访问排队等待甚至超时。所以,传统的PHP框架+PHP-FPM原生对大模型支持不够友好。
99客服系统采用的是webman框架,自身性能是传统框架的数倍,再加上它可以支持非阻塞调用大模型接口,这让99客服系统可以支持几千甚至上万的大模型并发调用。极大的提升了系统吞吐量,让每个用户的返回都丝滑流畅。
四 知识库代码片段
下面为示意代码,包含意图识别、段路径匹配策略、多路召回、阈值过滤、RRF排序、模型选择排序、耗时统计、最终回复等
<?php
declare(strict_types=1);
use Webman\Openai\Embedding;
use Webman\Openai\Chat;
/** 段路径粗意图:如 /kb/pre /kb/post,决定知识范围与模型 profile */
function intent_from_segment_path(string $path): string
{
if (str_contains($path, '/after-sales')) {
return 'after_sales';
}
if (str_contains($path, '/pre-sales')) {
return 'pre_sales';
}
return 'general';
}
/** 全文索引召回 */
function recall_fulltext(string $bid, string $query, int $k): array
{
return [
['id' => 'c1', 'text' => '退换货自签收 7 日内…', 'score' => 0.41],
['id' => 'c2', 'text' => '保修期以发票日期为准…', 'score' => 0.38],
];
}
/** 向量召回:返回 [{id, text, score}, ...] */
function recall_vector(string $bid, array $queryVector, int $k): array
{
return [
['id' => 'c2', 'text' => '保修期以发票日期为准…', 'score' => 0.86],
['id' => 'c9', 'text' => '安装服务另计费…', 'score' => 0.71],
];
}
function filter_by_min_score(array $hits, float $min): array
{
return array_values(array_filter($hits, static fn ($h) => ($h['score'] ?? 0) >= $min));
}
/** RRF:倒数排名融合,k 常取 60 */
function rrf_fuse(array $lists, int $topN, int $k = 60): array
{
$scores = [];
foreach ($lists as $list) {
$rank = 1;
foreach ($list as $hit) {
$id = $hit['id'];
$scores[$id] = ($scores[$id] ?? 0) + 1.0 / ($k + $rank);
if (!isset($scores['_text_' . $id])) {
$scores['_text_' . $id] = $hit['text'];
}
$rank++;
}
}
arsort($scores);
$out = [];
foreach ($scores as $id => $s) {
if (str_starts_with((string)$id, '_text_')) {
continue;
}
$out[] = ['id' => $id, 'text' => (string)($scores['_text_' . $id] ?? ''), 'rrf' => $s];
if (count($out) >= $topN) {
break;
}
}
return $out;
}
/** 不同模型或温度配置 **/
function pick_model_profile(string $intent): array
{
return match ($intent) {
'after_sales' => ['model' => 'gpt-4o-mini', 'temperature' => 0.1],
'pre_sales' => ['model' => 'gpt-4o-mini', 'temperature' => 0.4],
default => ['model' => 'gpt-4o-mini', 'temperature' => 0.2],
};
}
function build_system_prompt(array $chunks): string
{
$buf = "仅依据下列片段回答;缺资料则说明无法确认并建议人工。\n";
foreach ($chunks as $i => $c) {
$n = $i + 1;
$buf .= "[{$n}] {$c['text']}\n";
}
$buf .= "要求:关键结论附引用编号,如 [1][2]。";
return $buf;
}
/**
* @return array{reply:string, meta:array}
*/
function rag_answer_pipeline(
string $bid,
string $userQuery,
string $segmentPath,
string $embeddingApi,
string $embeddingKey,
string $embeddingModel,
string $chatApi,
string $chatKey,
): array {
$t0 = microtime(true);
$meta = ['phases' => []];
$intent = intent_from_segment_path($segmentPath);
$meta['intent'] = $intent;
$meta['phases']['intent_ms'] = (microtime(true) - $t0) * 1000;
$tEmb = microtime(true);
$emb = new Embedding(['apikey' => $embeddingKey, 'api' => $embeddingApi]);
$embRes = $emb->create([
'model' => $embeddingModel,
'input' => $userQuery,
'encoding_format' => 'float',
]);
$vec = $embRes['data'][0]['embedding'] ?? [];
$meta['phases']['embedding_ms'] = (microtime(true) - $tEmb) * 1000;
$tRe = microtime(true);
$fts = filter_by_min_score(recall_fulltext($bid, $userQuery, 20), 0.25);
$vecHits = $vec !== []
? filter_by_min_score(recall_vector($bid, $vec, 20), 0.20)
: [];
$meta['phases']['recall_ms'] = (microtime(true) - $tRe) * 1000;
$meta['recall_counts'] = ['fts' => count($fts), 'vector' => count($vecHits)];
$tFu = microtime(true);
$fused = rrf_fuse([$fts, $vecHits], 6);
$meta['phases']['rrf_ms'] = (microtime(true) - $tFu) * 1000;
$meta['citations'] = array_map(static fn ($c) => $c['id'], $fused);
$profile = pick_model_profile($intent);
$system = build_system_prompt($fused);
$tChat = microtime(true);
$reply = '';
$chat = new Chat(['apikey' => $chatKey, 'api' => $chatApi]);
$chat->completions([
'stream' => false,
'model' => $profile['model'],
'temperature' => $profile['temperature'],
'messages' => [
['role' => 'system', 'content' => $system],
['role' => 'user', 'content' => $userQuery],
],
], [
'complete' => static function (array $res) use (&$reply) {
$reply = $res['choices'][0]['message']['content'] ?? '';
},
]);
$meta['phases']['chat_ms'] = (microtime(true) - $tChat) * 1000;
$meta['phases']['total_ms'] = (microtime(true) - $t0) * 1000;
$meta['model'] = $profile['model'];
return ['reply' => $reply, 'meta' => $meta];
}其中比较重要的是文档及片段召回的统计信息,包括意图识别耗时、提炼出最终问题是什么、向量召回耗时、最终引用文档信息(包括文档名、召回时分数信息等),大模型选择排序耗时、大模型最终响应耗时等,这些信息对于知识库各个环节的调优非常重要,我们根据这些统计做了大量的提示词调优、知识库索引调优等工作,使得召回率、相关度、回复满意度得到了大幅度提升。
篇幅有限,以上只能粘贴示意代码。
获取完整RAG知识库+AI智能客服源码请访问 客服系统源码
知识库+客服效果演示
知识库主页面
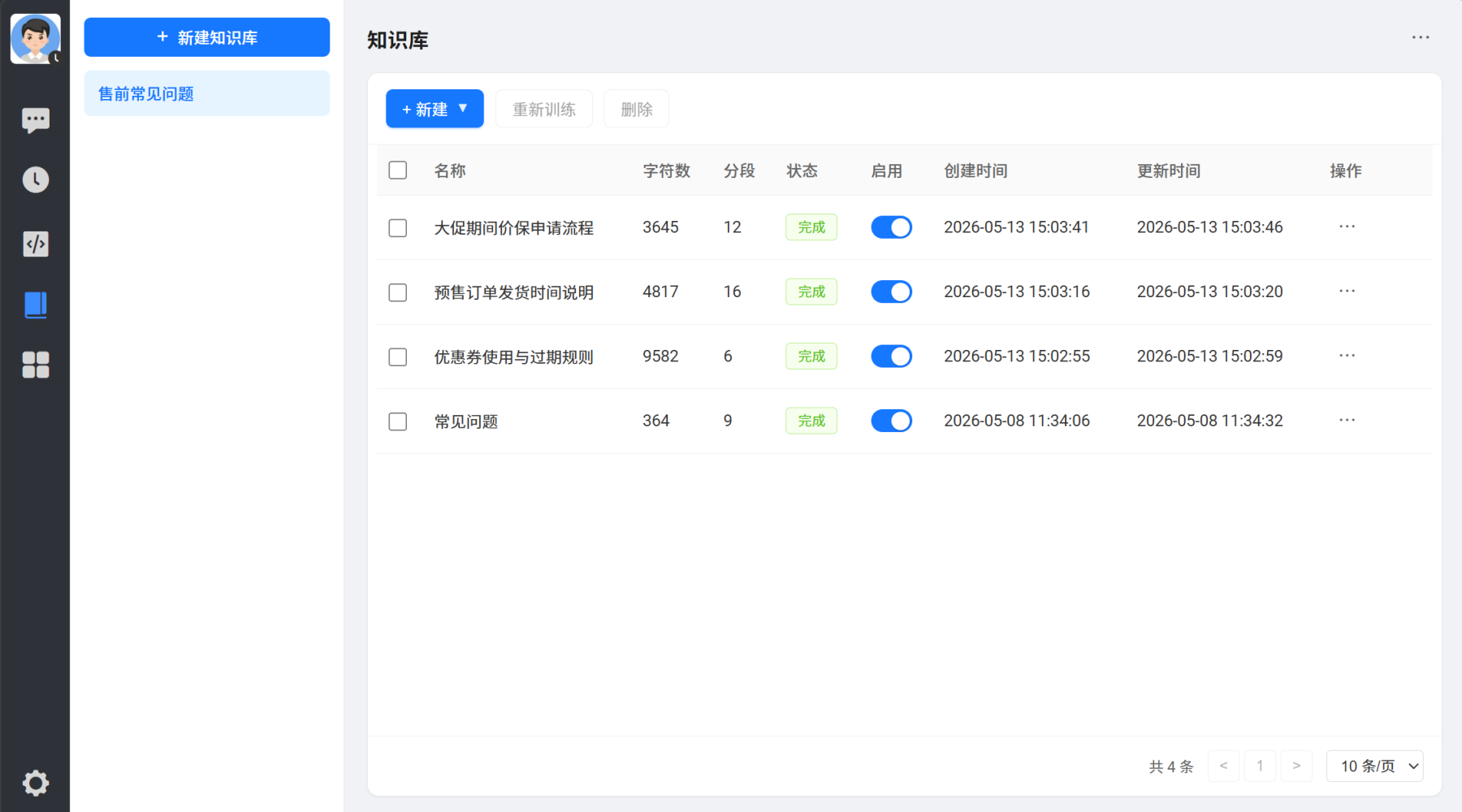
知识库主页面可以创建知识库以及批量上传文档或者手动填写文本。文档支持包括 txt、md、word、excel、ppt、pdf等格式,上传后可选择自动或手动分割文档,最终会自动训练。
知识库分段
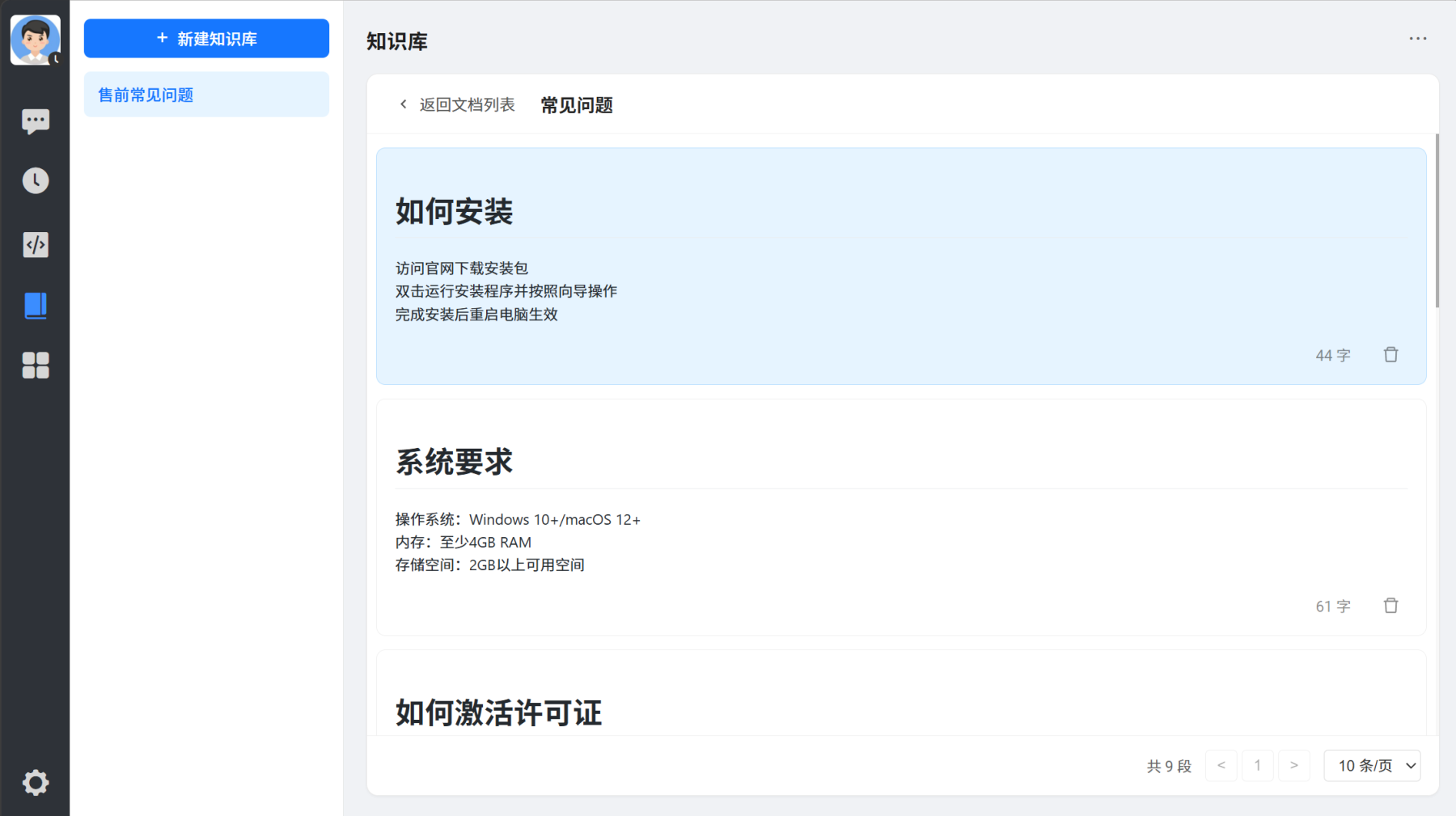
可以查看知识库分段内容,可以查看编辑分段内容和索引,包括标题索引和问题索引。可删除分段。
总管理后台大模型设置
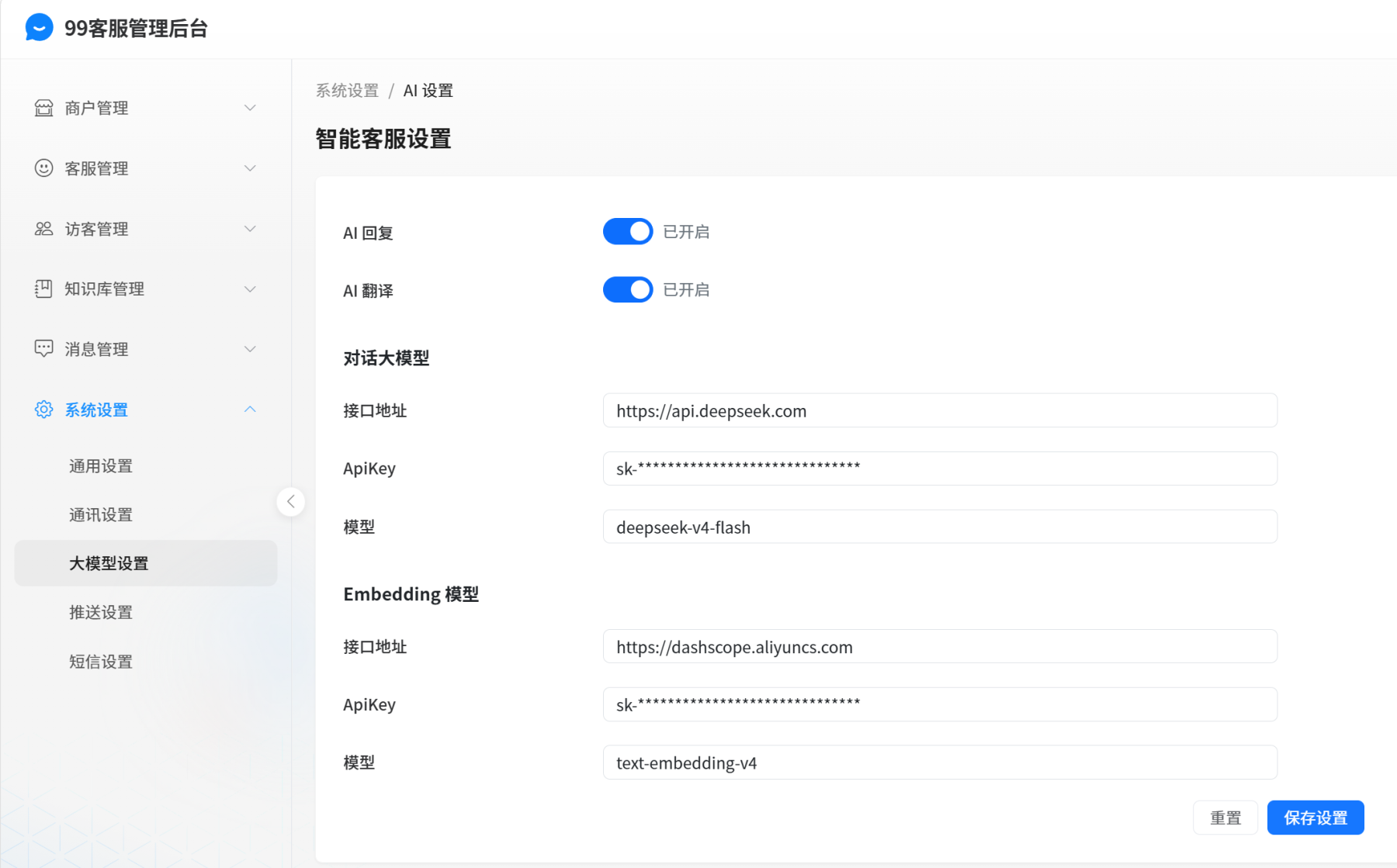
总管理后台可以设置大模型的相关参数,例如apikey和模型名。这些参数涉及到训练、智能回复等流程。
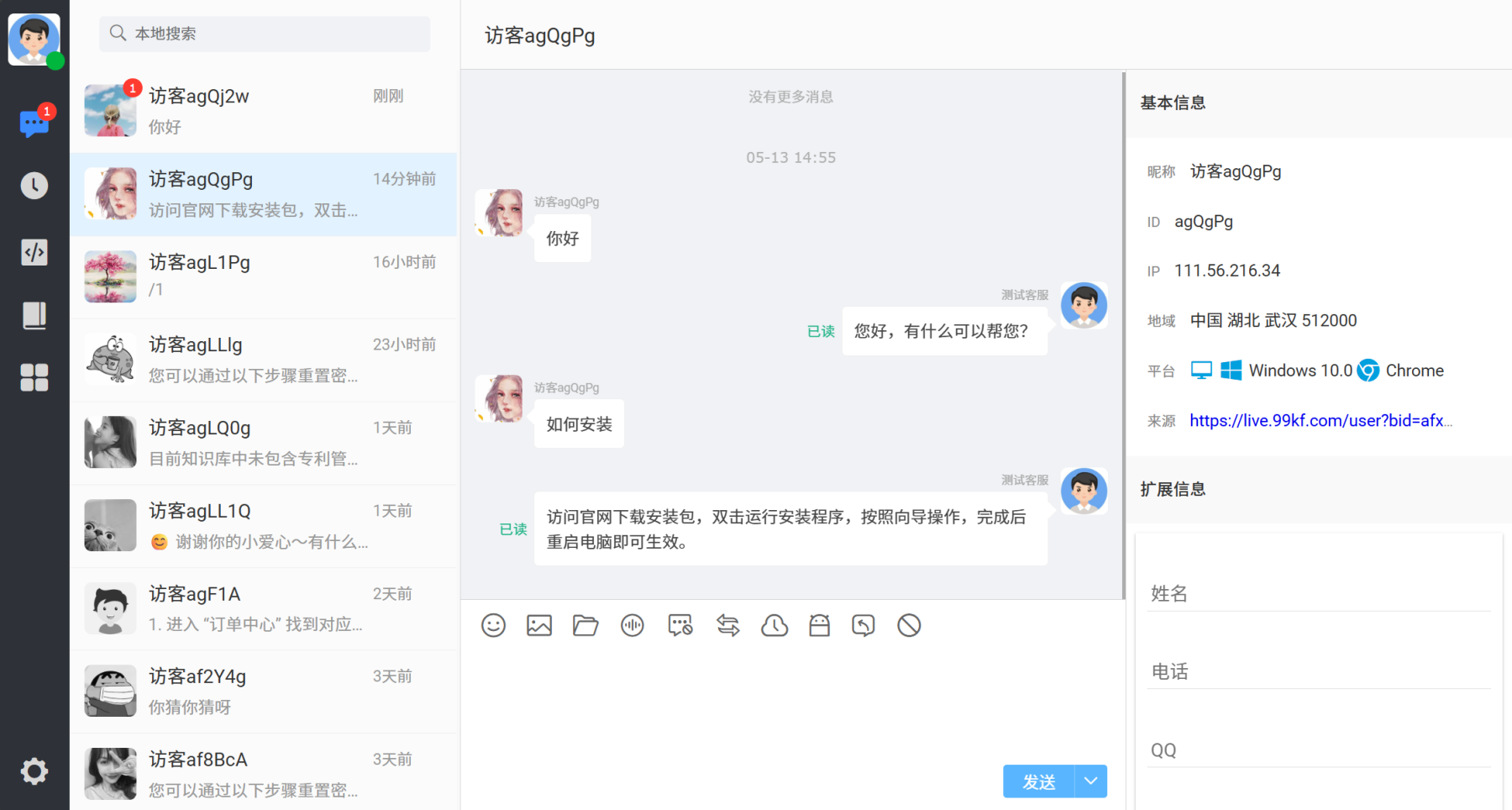
自动回复
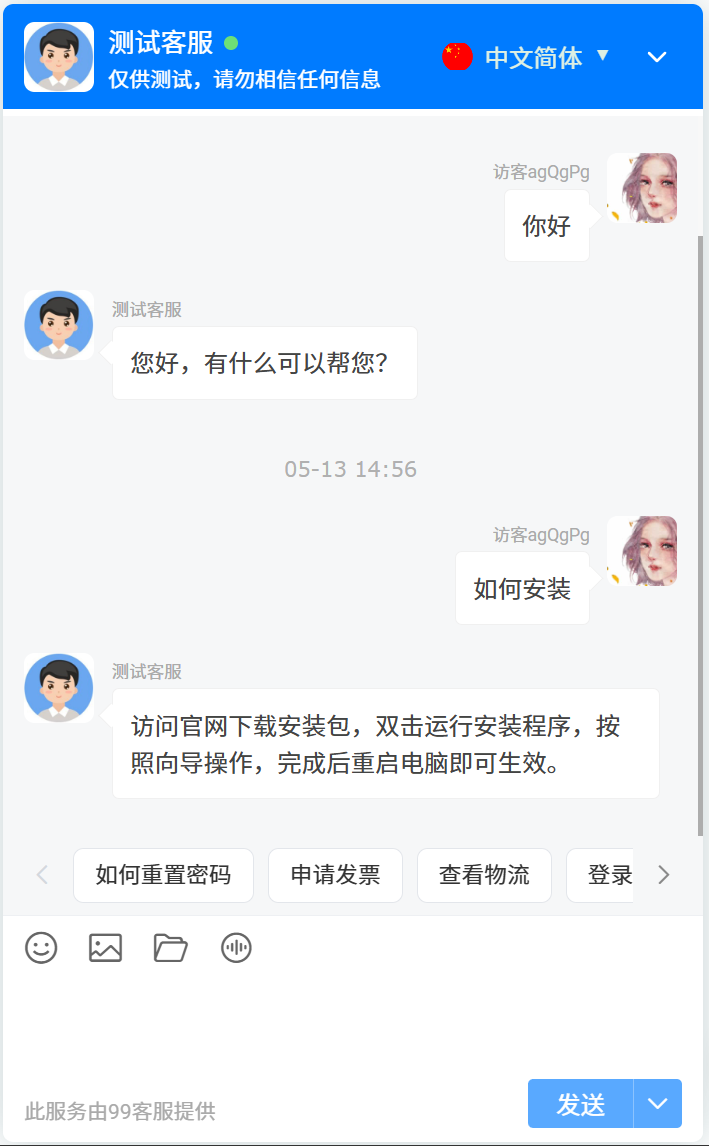
当用户提出的问题属于知识库范围内的问题时,客服系统会自动利用RAG知识库检索知识,并根据知识回复客户。





我最近也在做大模型知识库,没有头绪,php+大模型的文章太少了