gateworker 分布式部署延迟好几分钟
问题描述
这里写描述
gateworker 分布式部署延迟好几分钟
register 和 gateworker mysql 一台服务器简称A ,businessworker 单独一台 简称B,目前
B onmesseage 接受到消息比客户端发送的消息晚了好几分钟
[ 2023-11-11T17:31:58+08:00 ][ log ] 请求参数:{"command":,"api_version":"","data":{"addr":"","cpuname":"","iflist":[{"ifaddr":"","ifmac":"14:3d:f2:f3:c0:7f","ifname":""}],"last_ts":1699694855,"load":0.19705462455749512,"os":"","policy_ver":0,"port":"","uuid":""},"ts":1699694855}
ts的时间戳是1699694855 2023-11-11 17:27:35 日志接受的时间是 17:31:58 差了4分钟多, 目前A服务器cpu 60% B服务器 cpu 20% 这是什么原因呢

其中A服务器启动的start_register 和 start_gateway 目前调的 start_gateway 进程是8个
B服务器启动的是 start_business 进程是128 个
A 服务的status
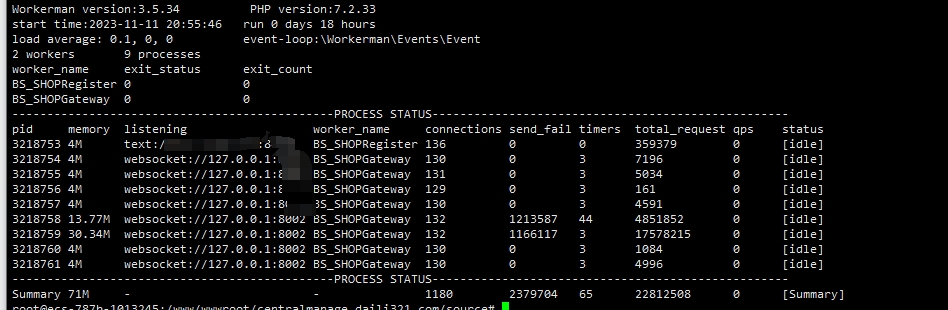
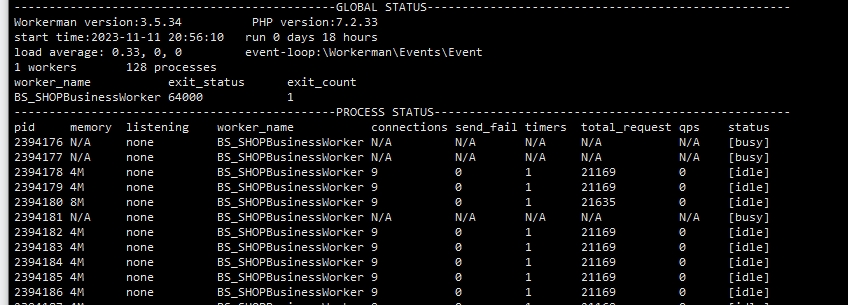
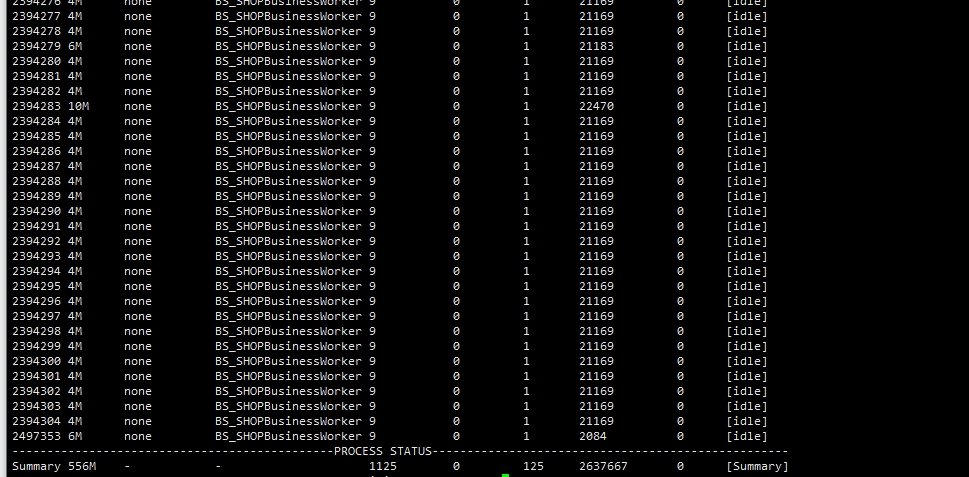
B服务器status
3个回答
年代过于久远,无法发表回答
月贡献榜
赞助商





热门问答
PHP聊天系统源码-即时通讯聊天源码 - 泡泡IM
【市场】操作日志 问题反馈
客服系统全套源码:大模型+RAG知识库解决方案,私有化部署AI智能客服源码
DeepSeek 本地部署教程(极其简单)
webman限流器发布
Webman AI + DeepSeek本地训练,打造私有知识库
直播系统聊天服务基于 Workerman,若同时在线 1 万人至 10 万人,技术上需要做哪些调整?
分享下你们用什么后台
大家能帮忙分享一下webman1,或者webman2的skill?或者官方出一个1、2的skill
PHP8.5来啦,php语言是否能上一个台阶,来聊聊!
把你的gateway,register,businessworker 配置都发出来。
还是说很少用户发送消息到达businessworker 都会延迟几分钟? 这样的话,就检查下网络环境以及配置文件。
也不排除你业务的问题
配置文件加上了
2023-11-12 13:52:08 pid:3218758 SendBufferToWorker fail. May be the send buffer are overflow. See http://doc2.workerman.net/send-buffer-overflow.html 现在A服务一直报这个
A 服务器和B服务器的负载都不高,就是有延迟
现在一分钟内有心跳的是5000个
请求量太大,服务端处理不过来了,导致延迟。
你们多少客户端在线啊,每秒心跳5000个,30秒一个心跳的话,都要15万在线了。
感觉是客户端一直在疯狂发请求请求量太大导致
B服务器的负载和cpu都不高
我看了在线数是1000多个
这个和延迟有关系吗
我把status放上去了
客户端1000个,心跳每秒5000个,说明客户端逻辑有问题,一直在疯狂发心跳请求,甚至业务请求也在疯狂发,业务处理不过来。你发的报错里的url地址里已经说明了原因了
但是cpu和负载都不高 ,我看负载高了才应该增加business 服务器
心跳不是每秒5000个 ,是看了心跳更新时间在一分钟内是5000个
看报错里的url,原因里面作者给你总结好了
但是一条一条对没有找到原因,按理说这些请求应该能处理好,mysql慢日志也没有
这个和延迟有关吗,这个报错运行一段时间才会报,一开始启动的时候没有这个报错
有关系,处理不过来,队列挤压,后面的请求等待前面的处理完才能被处理,所以延迟
文档里说的明明白白的
负载和cpu 不高 也可能出现这种处理不过来的情况吗
业务有IO请求,比如数据库,curl这些等IO等待的时候不占用本地cpu的。比如一个SQL请求耗时0.5秒,一个进程一秒钟只能处理2个请求。128个进程每秒只能处理256个请求,如果每秒有300个请求过来,请求就处理不过来了。但是你会发现cpu负载很低,因为大部分都在等待IO返回,不耗费cpu。内存够的你可以开512个进程,增加吞吐量。但是也不一定能处理得过来。你最好记录日志,每个请求处理耗时,每秒处理多少请求。
gateway 9 个进程,businesswork 128个进程。
你的描述:
CPU大量空闲,businessworker 大量空闲状态,出现部分worker 繁忙状态。
你的代码里面是不是有调用第三方API的动作?
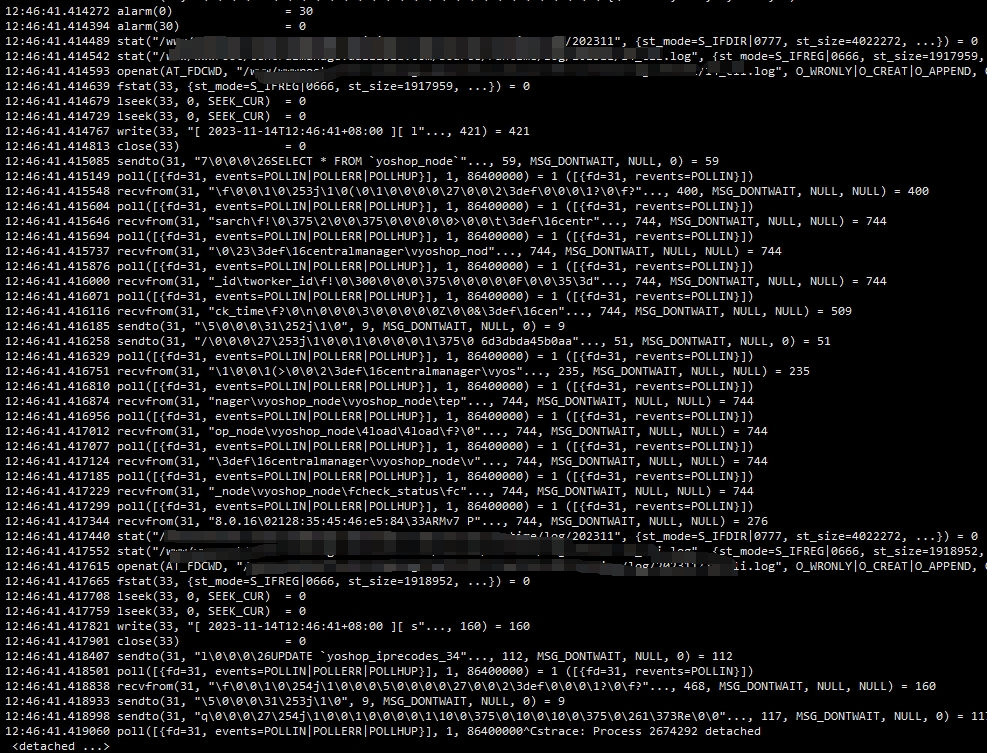
也可能是SQL执行太慢?strace -ttp [繁忙进程的PID] > output.log,你把日志文件截图发来看看呢?
截图发上来了