PHP+MYSQL求一个高并发方案

问题描述
内网http接口,高并发,要求响应在100ms内,单机需要支持5000+ QPS。
请求参数为订单ID(数字int类型),业务逻辑为判断本地数据库中订单是否存在,mysql大概100万条记录。
数据库中订单会随时增加,每天增加几百条。
服务器资源有限,越省资源越好。
php-fpm的框架都试过了,opcache全开最高也就200QPS左右,距离5000QPS相距甚远。
求一个高并发方案,现在打算用webman。redis能不用就不用。
用webman + bitmap完美解决 QPS 11万+,性能远远远元超预期,webman神一般的存在,详情见7楼回复。
17个回答
相关连接
年代过于久远,无法发表回答
月贡献榜
赞助商





热门问答
PHP聊天系统源码-即时通讯聊天源码 - 泡泡IM
【市场】操作日志 问题反馈
客服系统全套源码:大模型+RAG知识库解决方案,私有化部署AI智能客服源码
DeepSeek 本地部署教程(极其简单)
webman限流器发布
Webman AI + DeepSeek本地训练,打造私有知识库
直播系统聊天服务基于 Workerman,若同时在线 1 万人至 10 万人,技术上需要做哪些调整?
分享下你们用什么后台
目前用什么ai编码工具,以及搭配什么模型比较好?
PHP8.5来啦,php语言是否能上一个台阶,来聊聊!
是我我就这样试试:
public function existsxx(Request $request){
if(Redis::exists($request->get(''oid)){
return 1;
}
// 查询库
....
}
为啥不用redis?
哥们我这几天也是一样的需求
固定每秒500 - 1000 请求,数据库基础数据30万 数据库每天新增几千数据
请求来时判断数据库中是否存在数据,数据内容为:(34 - 64位字符串)
webman 群友给我的建议是将数据同步给redis,从redis中判断(redis 理论每秒支持10万+查询并发)
一些开发群给我的建议是上GO JAVA (当然无视这些吊毛打心眼里看不起php)
区块链扫块?
人啊,要认清现实,不要指着个正常的拖拉机要他跑出F1的速度
给结论,不想上各类缓存手段就堆硬件
MySQL查询走PK基本是最快的了,
select * from tbl where pk = ?数据库查询内就几ms,算上网络消耗一来一回就二三十ms我给你算个数据
FPM要5000qps,意味着1秒内要创建/销毁5000MySQL连接,问题在哪看到了么
想啥呢,高并发不上redis
直接查mysql 扛不住呀,redis 是最好的处理方案 bitmap 你可以尝试一下,这个理论 最省redis内存,然后入库 还是用队列最好,webman进程多开一切,理论 5000qps 没啥问题 ,最好是 webman 和 redis 在一个机器 他们直接通信基本能做3ms以内,你可以试试
压测了下,走数据库QPS能达到9000+了,就是cpu有点高,快80%了
他的业务好像只需要判断存在不存在,直接可以存redis里面判断就可以了吧? 写入和修改另外处理了
webman常驻内存的,直接走webman内存缓存数据,数据不存在时再走mysql,我们试过,性能无敌,架构也不用做什么改动。
代码类似这样,压测试下
这个方案就是有点费内存,但是性能那是真的好,比redis缓存快好几倍
有情提示,记得开启控制器复用
用的static静态变量,不用开控制器复用。当然开了性能更高
这种怎么说呢,就是有点耗费内存,实际如果redis和webman 通信 内网 基本还是redis bitmap比较好一个512M 的 key就够用了 查询是 (0)1,5000qps应该问题不大
我单机应用缓存基本实现跟你差不多,缓存不用Redis,直接用内存
问题是 你每个进程 都得存全量数据了 100多万呢,10个进程 就相当于内存中存了1000万数据呀,内存估计占用很大
看情况,量大我存/dev/shm,多进程共享,写时加锁
这个很高级呀 ,没用过 这个怎么写??分享一下
握了草,这个性能太爆表了,11W+ QPS,无以言表... 。就是有点占用内存,每个进程50M+
即使不命中缓存都走MYSQL,QPS也有9000+ ...
其实就是文件缓存,但是文件是直接写在内存里,dev/shm你可以当成RamDisk,因为是单机应用,所以也不在乎
主打一个简单...
怎么样 webman 猛不猛?吓一跳 吧 哈哈
单机应用的前提下,APCu之类不走网络的缓存方式其实比Redis快很多
@longlong 之前没用过webman框架嘛?
这性能没得说,我在想怎么把内存也降下去。内存再降下去就是几乎最完美的方案了。
我尝试让AI给我写一个php版本的bitmap来解决
你这想法不错呀,哈哈
既要..还要,不存在这种东西,要不就是时间换空间,要不就是空间换时间
没有又快又不占内存吧,总要用一样换取另一样
让官方的AI帮忙写了个php版本的bitmap,完美解决内存占用问题,现在每个进程占用内存28M+(相比主进程就多了5M左右),可缓存1000万订单id。webman真是牛逼,webman的AI也牛逼...
代码,各位参考下
@longlong 有个问题 如果说订单ID 换成 订单号呢?bitmap 是不是不适用了 (34-64位长度的字符串)
过长 就肯定不适用了,不过你可以用 布隆过滤器 ,让ai帮你写一个 php版本的布隆过滤器 一样的
@longlong 你现在这么写 qps能有2W+ 嘛?
注意,使用BloomFilter扩展需要先安装该扩展。你可以使用pecl命令来安装扩展,例如pecl install BloomFilter。安装完成后,你可以在PHP代码中使用BloomFilter类。
需要注意的是,布隆过滤器是一个概率型数据结构,因此在判断元素是否存在时,可能会出现一定的误判率。误判率取决于过滤器的大小和哈希函数的数量。在使用布隆过滤器时,需要根据实际情况来选择适当的过滤器大小和哈希函数数量,以平衡误判率和空间效率的要求。
这玩意有误差啊
其实 看量大小 ,如果量不是很大 ,可以redis 集合 是最简单的,不要在集合中查询 ,直接sadd 是最好的,这玩意效率高
@tanhongbin webman+bitmap 也是11W QPS
这个有点猛呀,不过你新添加的数据 怎么往bitmap里面放呀?
不存在就读下数据库,然后set进去,上面忘记写了
哦哦,方案可以 就是重启 还得重新写 ,写一个系统重新启动 ,直接把数据全写进去,就完美了,还有哪个查表 可以用省内存方式的那种写法
@kspade 字符串类型的订单号没办法用bitmap,直接用 @six 的方案,30万订单占用50M内存,完全可以接受。
@longlong
有点没看明白 上面@six 的方案 是否可以写成一个公用的class ,然后再各个控制器方法中调用?
还是说必须放在Controller 里面 protected static function get($id) 定义后调用
我觉得@six 的是不是最佳方案也应该是在启动项目时,把x表内所有数据给缓存到内存中去?
可以封装成公共类,@six的方案就是第一次请求时从数据库载入,也可以做成启动时就缓存到内存去。
最好是 启动就把数据缓存到内存中 ,webman就能实现,里面有一个随着 进程启动执行的类
config/bootstrap.php 学习了,我去实践一下
// 初始化缓存
if (!static::$data) {
ini_set('memory_limit', '512M');
static::$data = array_flip(Db::table('orders')->pluck('id')->toArray());
}
其中 Db::table('orders')->pluck('id')->toArray() 假设orders 表有100万条数据,这个语句应该要耗时挺久吧?我用think 感觉不利索呢
制器复用开跟不敢有啥区别?@six
@kspade 我这阿里云服务器,本地部署的mysql,100万耗时1秒左右
没有能力只能默默敬佩
按照订单后后缀做分表
你认真的吗?瓶颈在哪里你都没弄清楚,才100万的数据你给说说分表?
这个问题不是分表解决的。。。5000QPS每秒。。你分5000个表都没用。 单MYSQL 链接 销毁 都给你干嗝屁。。
php-fpm 每次请求都建立销毁MYSQL链接,性能太低了,我机器上只有200QPS
用 Wind Framework,你这每天几百条数据,单机 5000+ QPS 用这个框架,单个 HttpServer 进程轻轻松松,我们每天处理百万条数据,单机两个进程轻轻松松。
你们用wind Framework,用到不兼容的composer依赖,都是自己改造嘛?
用webman V5的协程+redis 轻轻松松几十万QPS
这个协程 redis 为啥我用着干啥 和直接用redis 没啥区别 ,性能 感觉是一样的,因为redis足够快呀
数据分块 同时查
有时间写个demo嘛大佬~ 学习下
分享例子 携程怎么玩的 我一直没搞懂
static public function httpRequest(string $url, string $method = 'GET', array $headers = [], array $data = [], bool $log = false) : string
{
$start_time = microtime(true);
$options = [
'max_conn_per_addr' => 128, // 每个域名最多维持多少并发连接
'keepalive_timeout' => 15, // 连接多长时间不通讯就关闭
'connect_timeout' => 30, // 连接超时时间
'timeout' => 30, // 请求发出后等待响应的超时时间
];
$http = new Client($options);
//$http = \support\Container::get('Workerman\Http\Client');
$postData = in_array('application/json',$headers)?json_encode($data):$data;
$response = $http->request($url, [
'method' => $method,
'version' => '1.1',
'headers' => $headers,
'data' => $postData,
]);
$end_time = microtime(true);
$res = $response->getBody()->getContents();
$logStr = json_encode(['url' => $url,'method' => $method,'response' => json_decode($res),'time' => ($end_time - $start_time) . 's']);
if($log) {
//第三方请求日志
Log::channel(self::$httplog)->info($logStr,$data);
}
return $res;
}
协程请求第三方接口的代码
前提是 composer "workerman/workerman": "v5.0.0-beta.5",
"revolt/event-loop": "1.0.1",
"workerman/http-client": "2.0.1",
这三个包
我帮你美化下
我这个协程 不一定正确 ,你们还是 自己实现最好 ,万一不对 就坑人了
guzzle 好像自带有?
不是guzzle是workerman的http组件
老哥这个注释了,是复用Client对象会出问题吗?//$http = \support\Container::get('Workerman\Http\Client');
不会 我为了测试 用的
先建立一个md5文件夹,把注释打开生成100万条订单数据
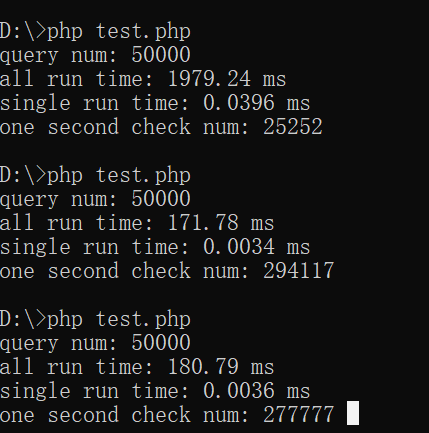
然后运行测试代码 直接用文件检测
单订单号检测和随机订单号检测速度差距还是挺大的
但是可以满足楼主的需求
Linux服务器上实测也差不多
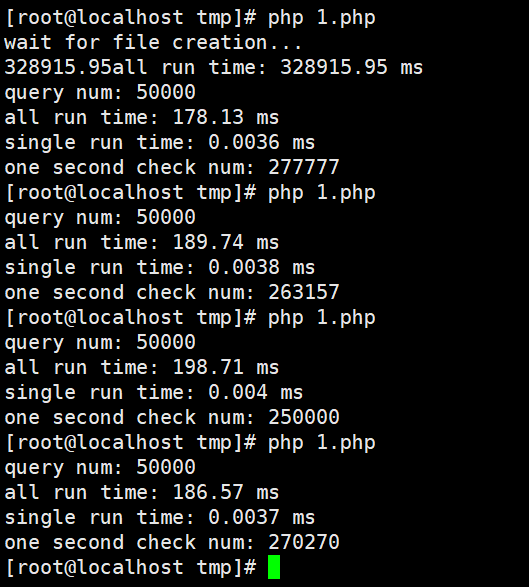
你这个开了多少进程?还有用的是什么软件压测的,我看你的压测时间太短了
[bitmap容量*(子进程数-1)]的内存。使用共享内存保存bitmap,既节省内存,又无IO。
https://www.php.net/manual/zh/book.shmop.php
webman 上实践过没?
这东西早玩烂了,对于PHP来说,既要……又要……,这是唯一的办法。
看了一下这个 如果要存入100万数据,还是很麻烦啊, 感觉就和tp的 cache 一样
何来跟tp的cache一样?shmop函数的唯一弊端是最小读写单元是8位,写入时可能需要加锁,但是锁字节即可,粒度很小,按楼主所言每日增加几百条,即使使用文件锁也毫无性能问题。
单机应用用shm的性能真不是redis可以比的
真羡慕你们懂那么多。我研究研究去,最近对这块正好有需求,
这玩意多思考,多想多测试啥都明白了
共享内存的缺点是需要序列化和反序列化, 这个难道不是最慢的吗
求教
要怎么初始化 才可以在所有进程的控制器方法中使用? 包括 redis 消费中 可以调用判断是否存在
多思考,多尝试,多测试
参考文档https://www.workerman.net/doc/webman/others/bootstrap.html
初始化定义
读取初始化变量
定义静态变量
测试结果
我有个问题哈,这种写法的话,对于新增或者删除的数据,无法跨进程啊。 比如http开了8个进程处理订单号,自定义进程4个用于处理新增/删除的数据,这种如何更新8个http进程中的内存数据呢。
学习了
学习了
收藏一下
学习了