webman的爬山虎插件(爬虫)
简介
webman的爬山虎插件: 让爬取工作变得更加简单。
安装
composer require blogdaren/webman-phpcreeper效果图
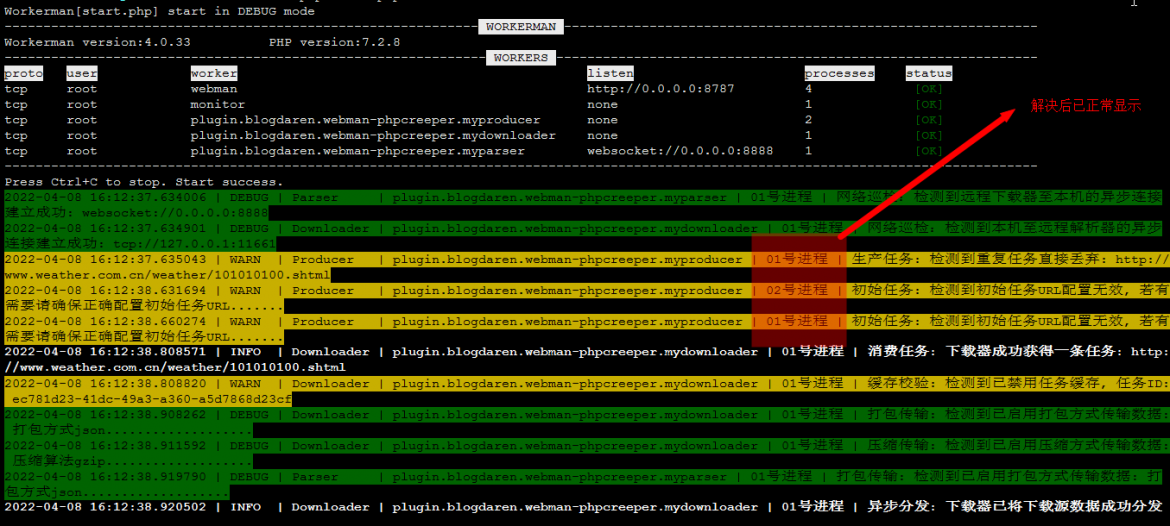
使用说明
- 编写一个爬虫非常简单: 配置搞定以后,只需要在对应容器内的
onXXXX回调方法内编写业务逻辑即可。 - 由于爬虫应用相对WEB应用而言比较独立,所以app内的爬虫目录结构请自行部署。
- 首先在自己的app项目下手动创建有效的爬虫目录。
- 在爬虫目录内创建相应的容器【生产器、下载器和解析器】句柄类Hanlder。
注意事项
- 爬虫自有的配置文件要保持相对独立;
- process配置内的关于进程构造函数的配置一般不要动;
- 目前需要手动设置下载器的$downloader->setClientSocketAddress([]);
- 依赖redis服务,所以务必启动redis-server;
- 按照规范每一个独立的容器实例最好对应唯一的一个Handler;
目前Debug界面第5列数据【已经解决: 版本更新到 >=1.01】【即进程编号列】显示有异常,待有结果了再来更新下,不过对抓取业务没有任何影响;
爬山虎技术文档
- 爬山虎中文官方网站:http://www.phpcreeper.com
- 中文开发文档主节点:http://www.blogdaren.com/docs/
- 中文开发文档备节点:http://www.phpcreeper.com/docs/
- 爬山虎内核项目地址:https://github.com/blogdaren/PHPCreeper
举个栗子
模拟需求是抓取未来7天内的天气预报
1、创建爬虫目录:app/spider
2、创建生产器句柄类文件 app/spider/Myproducer.php
<?php
/**
* @script Myproducer.php
* @brief 生产器Handler
* @author blogdaren<blogdaren@163.com>
* @version 1.0.0
* @modify 2022-04-01
*/
namespace app\spider;
use Workerman\Timer;
class Myproducer extends \Webman\PHPCreeper\Producer
{
/**
* @brief 抓取未来7天内的天气预报DEMO
*
* @return mixed
*/
public function makeTask()
{
//Create One Task
$task = array(
'url' => 'http://www.weather.com.cn/weather/101010100.shtml',
'rule' => array(
'time' => ['div#7d ul.t.clearfix h1', 'text'],
'wea' => ['div#7d ul.t.clearfix p.wea', 'text'],
'tem' => ['div#7d ul.t.clearfix p.tem', 'text'],
'wind' => ['div#7d ul.t.clearfix p.win i', 'text'],
),
'context' => array(
'cache_enabled' => true,
'cache_directory' => '/tmp/DownloadCache4PHPCreeper/download/',
'allow_url_repeat' => true,
),
);
$this->newTaskMan()->createTask($task);
}
/**
* @brief onProducerStart
*
* @param object $producer
*
* @return mixed
*/
public function onProducerStart($producer)
{
//$this->makeTask();
Timer::add(2, [$this, "makeTask"], [], true);
}
/**
* @brief onProducerStop
*
* @param object $producer
*
* @return mixed
*/
public function onProducerStop($producer)
{
}
/**
* @brief onProducerReload
*
* @param object $producer
*
* @return mixed
*/
public function onProducerReload($producer)
{
}
}3、创建下载器句柄类文件 app/spider/Mydownloader.php
<?php
/**
* @script Mydownloader.php
* @brief 下载器Handler
* @author blogdaren<blogdaren@163.com>
* @version 1.0.0
* @modify 2022-04-01
*/
namespace app\spider;
class Mydownloader extends \Webman\PHPCreeper\Downloader
{
/**
* @brief onDownloaderStart
*
* @param object $downloader
*
* @return mixed
*/
public function onDownloaderStart($downloader)
{
$downloader->setClientSocketAddress([
'ws://127.0.0.1:8888',
]);
}
/**
* @brief onDownloaderStop
*
* @param object $downloader
*
* @return mixed
*/
public function onDownloaderStop($downloader)
{
}
/**
* @brief onDownloaderReload
*
* @param object $downloader
*
* @return mixed
*/
public function onDownloaderReload($downloader)
{
}
/**
* @brief onDownloaderMessage
*
* @param object $downloader
* @param string $parser_reply
*
* @return mixed
*/
public function onDownloaderMessage($downloader, $parser_reply)
{
//pprint($parser_reply, __METHOD__);
}
/**
* @brief onBeforeDownload
*
* @param object $downloader
* @param array $task
*
* @return mixed
*/
public function onBeforeDownload($downloader, $task)
{
//$downloader->httpClient->setConnectTimeout(3);
//$downloader->httpClient->setTransferTimeout(10);
//$downloader->httpClient->setHeaders(array());
//$downloader->httpClient->setProxy('http://180.153.144.138:8800');
}
/**
* @brief onStartDownload
*
* @param object $downloader
* @param array $task
*
* @return mixed
*/
public function onStartDownload($downloader, $task)
{
}
/**
* @brief onAfterDownload
*
* @param object $downloader
* @param array $download_data
* @param array $task
*
* @return mixed
*/
public function onAfterDownload($downloader, $download_data, $task)
{
//pprint($downloader->getDbo('test'), __METHOD__);
}
}4、创建解析器句柄类文件 app/spider/Myparser.php
<?php
/**
* @script Myparser.php
* @brief 解析器Handler
* @author blogdaren<blogdaren@163.com>
* @version 1.0.0
* @modify 2022-04-01
*/
namespace app\spider;
class Myparser extends \Webman\PHPCreeper\Parser
{
/**
* @brief onParserStart
*
* @param object $parser
*
* @return mixed
*/
public function onParserStart($parser)
{
}
/**
* @brief onParserStop
*
* @param object $parser
*
* @return mixed
*/
public function onParserStop($parser)
{
}
/**
* @brief onParserReload
*
* @param object $parser
*
* @return mixed
*/
public function onParserReload($parser)
{
}
/**
* @brief onParserMessage
*
* @param object $parser
* @param object $connection
* @param string $download_data
*
* @return mixed
*/
public function onParserMessage($parser, $connection, $download_data)
{
/*
*$rule = array(
* 'hotline' => ['div.qxfw-body > p:eq(1)', 'text'],
*);
*$data = $parser->extractor->setHtml($download_data)->setRule($rule)->extract();
*pprint($data, __METHOD__);
*/
}
/**
* @brief onParserFindUrl
*
* @param object $parser
* @param string $url
*
* @return mixed
*/
public function onParserFindUrl($parser, $url)
{
return $url;
}
/**
* @brief onParserExtractField
*
* @param object $parser
* @param string $download_data
* @param array $fields
*
* @return mixed
*/
public function onParserExtractField($parser, $download_data, $fields)
{
!empty($fields) && pprint($fields, __METHOD__);
}
}5、修改插件的process配置文件设置对应的Handler
<?php
use app\spider\Myproducer;
use app\spider\Mydownloader;
use app\spider\Myparser;
return [
'myproducer' => [
'handler' => Myproducer::class,
'listen' => '',
'count' => 1,
'constructor' => ['config' =>
include('spider/global.php')
],
],
'mydownloader' => [
'handler' => Mydownloader::class,
'listen' => '',
'count' => 1,
'constructor' => ['config' =>
include('spider/global.php')
],
],
'myparser' => [
'handler' => Myparser::class,
'listen' => 'websocket://0.0.0.0:8888',
'count' => 1,
'constructor' => ['config' =>
include('spider/global.php')
],
],
];13个评论
年代过于久远,无法发表评论

phpcreeper
11926
积分
0
获赞数
0
粉丝数
2015-11-07 加入
很不错
安装不了
composer require blogdaren/webman-phpcreeper
Using version ^1.0 for blogdaren/webman-phpcreeper
./composer.json has been updated
Running composer update blogdaren/webman-phpcreeper
Loading composer repositories with package information
Updating dependencies
Your requirements could not be resolved to an installable set of packages.
Problem 1
Use the option --with-all-dependencies (-W) to allow upgrades, downgrades and removals for packages currently locked to specific versions.
You can also try re-running composer require with an explicit version constraint, e.g. "composer require blogdaren/webman-phpcreeper:*" to figure out if any version is installable, or "composer require blogdaren/webman-phpcreeper:^2
.1" if you know which you need.
Installation failed, reverting ./composer.json and ./composer.lock to their original content.
升级爬山虎内核到最新版:
composer update blogdaren/phpcreeper:v1.4.3Windows不支持啊
不支持windows
学习
怎么分布式部署啊?这个如果要分布式是不是不行?
【1】分布式和分离式都是支持的,和workeman的的分布式分离式模型完全一致。
【2】文档分享已经久远,更多的更新参看爬山虎项目以及插件的官方手册,或者进爬山虎技术群问询。
如何使用pyppeteer 或者puppeteer 来抓取内容。如何设置代理呢
目前需要自行编写插件扩展,后续可能会考虑支持。
对于那些内容是根据js动态生成的页面能不能抓?比如,网页加载后,js才去加载主要内容。
这个爬不了,需要使用Selenium
目前需要自行编写插件扩展,比如包装下无头浏览器:phantomjs, 后续可能会考虑支持。
2022-12-28 16:37:22.323509 | ERROR | Producer | plugin.blogdaren.webman-phpcreeper.myproducer | 01号进程 | 生产任务: 检测到任务URL配置无效, 请确认是否已经正确设置任务URL.......
都是安装的最新的,按照上面复制的天气采集代码来的
得替换下。$this->newTaskMan()->createTask($task);
【1】关于URL无效的问题,先升级爬山虎插件和爬山虎引擎到最新版试下看;
【2】现在使用短API即可:$this->createTask($task);
【3】文档分享已经久远,更多的更新参看爬山虎项目以及插件的官方手册,或者进爬山虎技术群问询。
文档上的这个打不开了
http://www.phpcreeper.com/docs/ProjectOverview/PHPCreeperAppFramework.html
感谢反馈,好了。
网页爬到后抽取有新的URL,如何放进去队列里面继续爬取,一直把所有的URL爬完?
【1】本质上每种容器都可以透析Task对象暴露的API,所以这么用就好了:$parser->createTask($task);
【2】文档分享已经久远,更多的更新参看爬山虎项目以及插件的官方手册,或者进爬山虎技术群问询。
如果有两个抓取网站,按照爬山虎文档多任务模式配置,一直提示设置
检测到任务URL配置无效, 请确认是否已经正确设置任务URL.......所以在webman下如果要有多个抓取任务是否要按爬山虎的一个任务在一个目录里那样配置?如果按那个方法配置,那在plugins里process.php里应该怎么配置多个Producer,download,parser 呢?
还有就是,抓取的频率只能通过Timer::add()来实现吗?我只在指定的时间内需要抓取数据,是否可以用crontab类似的定时任务来执行呢?
【1】关于URL无效的问题,先升级爬山虎插件和爬山虎引擎到最新版试下看;
【2】一般不需要,另对于多个任务有相应的API,即:$producer->createMultiTask($task);
【3】爬山虎的定时器和workerman一脉相承,既支持Timer用法,也支持Crontab用法。
【4】文档分享已经久远,更多的更新参看爬山虎项目以及插件的官方手册,或者进爬山虎技术群问询。
请问能抓取js渲染的数据吗?
目前需要自行编写插件扩展,比如包装下无头浏览器:phantomjs, 后续可能会考虑支持。