TCP 异常断开
背景:
1、 tcp client 终端为智能手表,目前同时在线大约有6000台,通过服务器记录发现在白天的时候,一些手表的 tcp 断开比较频繁,到晚上的时候不怎么断开(晚上是业务低谷,各个手表基本不怎么上传数据到服务器)。
2、手表使用的是2G 网络,活动范围都在城市内。
3、workerman 运行截图:

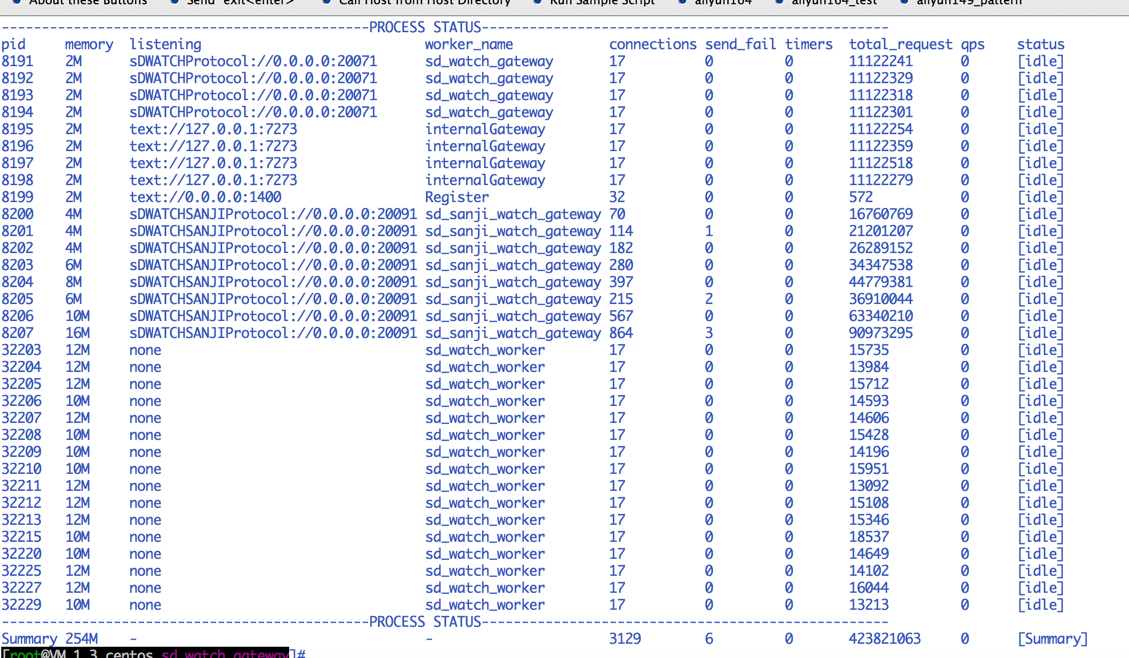
4、已经按照“Linux内核调优”章节介绍 的方法调优了系统配置
5、机器配置:腾讯云 4核8G 内存,服务器负载稳定在0.15
6、设备在线时会保持 TCP 上连接,频繁传输数据(每分钟内都会上传)
7、有业务自身实现的心跳机制
向作者和大家请教:是否有办法判断 TCP 断开的原因?比如以下可能:
1.worker 进程超时严重
手表终端网络环境差
服务器配置有问题
能否指点一下排查的方向,以及 workerman 和我的服务器能否支持这么多设备同时在线
之前排查发现有业务 IO 阻塞,解决后情况好了很多,但还是有不少,请大家分享一点经验,非常感谢了。
我们产品目标是8万手表终端同时在线,该如何调优 workerman ?
2个回答
相关连接
年代过于久远,无法发表回答
月贡献榜
赞助商





热门问答
PHP聊天系统源码-即时通讯聊天源码 - 泡泡IM
【市场】操作日志 问题反馈
客服系统全套源码:大模型+RAG知识库解决方案,私有化部署AI智能客服源码
DeepSeek 本地部署教程(极其简单)
webman限流器发布
Webman AI + DeepSeek本地训练,打造私有知识库
直播系统聊天服务基于 Workerman,若同时在线 1 万人至 10 万人,技术上需要做哪些调整?
分享下你们用什么后台
目前用什么ai编码工具,以及搭配什么模型比较好?
PHP8.5来啦,php语言是否能上一个台阶,来聊聊!
首先感谢你这么详细的提问!
如果业务每个请求处理时间都足够快,支持8万设备在线是没问题的。
但是如果业务有一点慢,比如数据库操作一次需要0.05秒,假设8万设备每秒产生5000个操作数据库的请求,那么设备每秒产生的请求需要服务端耗时25秒才能处理完(多进程的情况下可以缓解),这样请求不断累积会出现业务延迟越来越严重。如果客户端设备有做超时断开操作,那么可能会导致大面积连接断开重连。往坏一点说,如果某些请求处理更慢些,例如慢sql 访问外部存储或者curl超时阻塞了几十秒,那个情况会变得更差。所以保证每个请求都能极快的处理是保持上万并发连接的关键。
目前总结的客户端连接断开的原因大概有以下几个方面:
1、设备所处环境网络不稳定
2、设备与服务器间没有用心跳来维持连接。心跳间隔最好小于60秒,大于60秒的心跳无法有效维持连接,有些可能需要的心跳间隔更小。
3、没有安装event扩展,导致单个进程无法维持超过1024个连接,多余的连接会有超时断开的情况
4、没有按照手册优化linux内核
例如内核进程打开文件数限制了单个进程只能维持1024个连接,多余连接超时断开
例如内核同时打开了net.ipv4.tcp_tw_recycle 和 net.ipv4.timestamp 导致处于nat网络的客户端连接超时
例如内核防火墙跟踪表 (net.netfilter.nf_conntrack_max)大小设置太低,无法应对大量连接,导致客户端连接超时或者断开
5、业务bug导致一些连接被错误的断开
6、设备bug导致连接断开
根据描述,白天设备连接断开比较频繁,夜晚比较稳定,我有点怀疑是由于白天很多用户活动与不同的环境导致,例如在电梯 地铁 地下室等环境网络比较差,连接断开。等到了信号好的地方又重新连接。
而夜里时大家都在睡觉,不会出现网络环境频繁变更的情况,自然比较稳定。
非常感谢提供的思路,看来问题很有可能出在业务有点慢的问题上。产品初期最关心的是实现业务逻辑,对于性能问题并不是很重视。我先从这个方向理一下,有进展再向您请教
请问楼主还在做手表吗?如何联系呢?有问题想请教您